
이번엔 오디오 신호 처리 분야 논문을 접하는 데 도움이 되는 Background에 대해서 알아보겠습니다.
LUFS(Loudness Units Relative to Full Scale)
오디오 신호의 음량을 측정하고 정량화하는 데 사용되는 단위입니다.
가청 주파수를 의미하며 인간이 느끼는 소리의 크기를 의미합니다.
마이너스 무한대에서 시작해서 소리가 커질수록 0에 가까워 집니다.
기존의 단위들은 같은 값이더라도 음악의 밸런스에 따라 사람이 체감되는 음량이 다르다는 문제점이 있습니다.
LUFS는 K-Weighting Filter를 통해 이러한 문제점을 해결합니다.
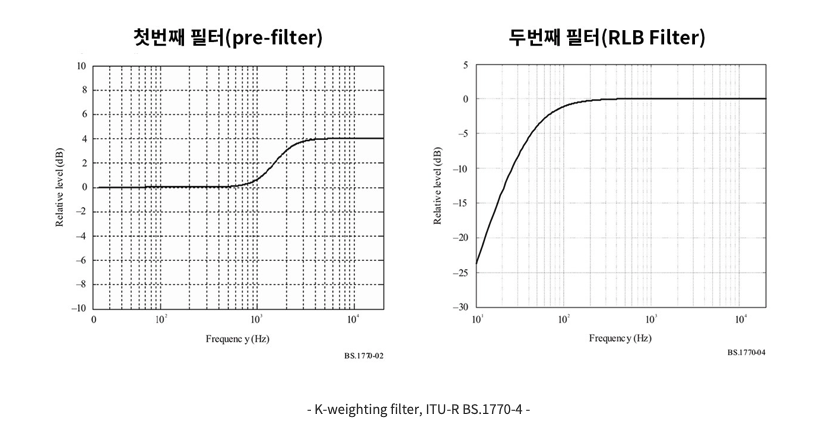
등청감곡선(인간의 청각에 기반한 그래프)을 반영하여 만들어진 필터를 통해 기존 단위들보다 사람이 체감하는 음량을 계산할 수 있습니다.
첫 번째 필터는 K-Weighting Filter로 사람의 머리와 귓바퀴 주위의 분산을 시뮬레이션하는 데 사용됩니다.
RLB 필터는 Revised Low Frequency B - Curve weighting의 약자로, 주로 저주파 영역에 대한 인간의 귀의 불감증을 반영하기 위해 사용됩니다.
LUFS는 규격이 ** ITU / EBU **가 존재합니다.
ITU(국제 전기통신연합)는 정보 통신 기술을 담당하는 유엔 기관입니다.
LUFS는 ITU R BS 1770 기준으로 표준화되었습니다.
이 규격은 오디오 레벨을 측정하고 평가하기 위한 표준화된 방법을 정의하며, LUFS 단위로 audio loudness를 측정합니다.
SDR(Signal-to-Noise Ratio)과 SIR(Signal-to-Interference Ratio)
SDR(신호 대 잡음 비율)
SDR은 전송된 신호와 주변 잡음의 강도나 에너지 간의 비율을 나타냅니다. 더 높은 SDR 값은 더 우수한 신호 품질을 나타냅니다. 즉, 신호가 잡음에 비해 더 강력하다는 것을 의미합니다. SDR은 주로 무선 통신에서 사용되며, 좋은 SDR은 통화 품질을 향상시키고 데이터 전송 속도를 높일 수 있습니다.
SIR(신호 대 간섭 비율)
SIR은 전송된 신호와 다른 신호 또는 간섭 신호의 강도나 에너지 간의 비율을 나타냅니다. 더 높은 SIR 값은 더 적은 간섭과 더 강력한 신호를 의미하며, 통신 시스템의 성능을 개선합니다.
간단히 말하면, SDR은 신호와 잡음 간의 비율을 나타내고, SIR은 신호와 간섭 간의 비율을 나타냅니다. 두 비율이 높을수록 통신 시스템의 성능이 향상되며, 더 나은 통신 품질 및 데이터 전송 신뢰성을 제공합니다.
SDR과 SIR 두 가지 지표는 높을수록 분리 작업이 더 정확하게 이루어졌다고 할 수 있지만, 이는 분리된 신호가 어떤 형태로 재구성되었느냐와는 관련이 없습니다. 따라서 더 높은 SDR과 SIR을 가지는 분리된 신호가 더 나은 음질을 제공할 수 있지만, 항상 그런 것은 아니며, 실제 음악 분리 시스템은 지각적인 음질을 평가하기 위해 청취자의 주관적인 평가 및 음성 처리 기술을 통합하여 고려해야 합니다.
시간 영역 모델(Time Domain Model) VS 주파수 영역 모델(Frequency Domain Model)
- 샘플 단위의 불연속성
시간 영역 모델은 입력 오디오를 직접 시간 단위로 분석하고 처리합니다. 이로 인해 예측된 신호가 원본 신호와 각 샘플에서 불연속성을 보일 수 있습니다. 이러한 불연속성은 실제 음악에서는 듣기 어렵지만 노이즈처럼 들릴 수 있으며 와이드 밴드 노이즈로 나타날 수 있습니다.
- STFT 프레임 단위의 불연속성
주파수 영역 모델인 Open-Unmix나 Spleeter는 입력 신호를 STFT와 같은 주파수 프레임 단위로 분석하고 처리합니다. 이는 프레임 간의 연결성을 유지하고 시간 단위 불연속성을 줄일 수 있는 이점을 제공합니다.
시간 영역 모델은 주파수 도메인에서 연결성을 부드럽게 보간하는 “overlap-and-add”방법을 사용하지 않습니다.
이 방법은 STFT를 사용하는 주파수 영역 모델에서 사용되며 연속성을 제공하고 와이드 밴드 노이즈를 줄이는 데 도움을 줍니다.
따라서 시간 영역 모델은 예측된 신호에서 샘플 단위의 불연속성과 급격한 변화를 더 자주 보일 수 있으며, 이로 인해 와이드 밴드 노이즈로 나타날 수 있습니다. 반면 주파수 영역 모델은 주파수 프레임 간의 연결성을 높이고, STFT 및 overlap-and-add와 같은 방법을 통해 시간적 불연속성을 보다 부드럽게 처리할 수 있으므로 노이즈 생성 측면에서 더 안정적으로 보일 수 있습니다.
- Overlap-and-add
신호 처리에서 주로 사용되는 기술 중 하나로, 오디오 신호와 같은 시계열 데이터를 재구성하거나 변환하는 데 유용한 방법
주요 목적은 오디오 신호를 분석 및 처리한 후 다시 합치는 과정에서 발생하는 신호 간의 연결성을 보존하고, 신호의 부드러운 이어 붙임을 보장하는 것입니다.
신호 분석: 먼저 입력 신호(음악, 음성)를 작은 프레임 또는 윈도우로 나눕니다. 이 윈도우는 주로 STFT 또는 다른 변환 방법을 사용하여 주파수 영역으로 변환됩니다. 이러한 작은 프레임은 신호를 작은 조각으로 나누어 주파수 정보를 추출하는 데 사용됩니다.
신호 처리: 각 프레임은 필터링, 스무딩, 에피소드 제거 등의 처리를 거칩니다. 주로 주파수 도메인에서 작업이 수행됩니다.
Overlap-and-add: 처리된 프레임은 다시 시간 영역으로 변환되고, 이러한 프레임을 겹쳐서(overlap) 원래 신호로 재구성됩니다. 이 과정에서 겹치는 부분은 중복된 부분입니다.
Overlap-and-add 방법은 신호의 재구성에서 발생하는 불연속성을 최소화하고 시간적 연속성을 보장하기 위해 사용됩니다. 이 방법을 사용하면 신호의 중복 부분을 적절히 가중치를 조절하여 신호를 원래의 길이와 일치하게 만들 수 있습니다. 이것은 오디오 신호를 변환하고 다시 재구성할 때 신호 간의 이어 붙임을 부드럽게 처리하는 데 도움이 됩니다.
Open-Unmix
Open-Unmix는 음원 분리 작업에 사용되는 딥러닝 모델 중 하나로, 주로 음성 신호를 다중 음원으로 분리하는 데 사용됩니다. Open-Unmix는 주파수-시간 도메인에서 주파수 스펙트로그램을 입력으로 받고, 분리된 음원의 스펙트로그램을 출력합니다. 다음은 Open-Unmix의 주요 구성 요소와 모델 구조에 대한 간단한 설명입니다.
입력 데이터:Open-Unmix 모델은 음성 신호의 주파수-시간 스펙트로그램을 입력으로 사용합니다. 스펙트로그램은 시간에 따른 주파수 성분의 에너지를 표현한 것이며, 주로 STFT(Short-Time Fourier Transform)를 사용하여 계산됩니다.
Convolutional Neural Network(CNN): Open-Unmix의 모델 구조에는 Convolutional Neural Network(CNN) 레이어가 포함됩니다. CNN은 입력 스펙트로그램을 처리하고 주파수 및 시간 정보를 추출하는 데 사용됩니다. CNN은 주로 주파수 방향의 특성을 학습합니다.
Long Short-Term Memory(LSTM) 레이어: CNN 다음에는 LSTM 레이어가 사용됩니다. LSTM은 순차적인 시간 정보를 고려하여 음원 분리 작업을 수행하는 데 도움을 줍니다. LSTM은 주로 시간 방향의 음성 특성을 학습합니다.
Soft Masking: Open-Unmix는 주파수-시간 스펙트로그램에 대한 소프트 마스크(soft mask)를 학습합니다. 소프트 마스크는 입력 스펙트로그램의 각 주파수 및 시간 슬롯에 대해 분리된 음원의 기여를 나타냅니다. 이러한 마스크를 사용하여 입력 스펙트로그램을 분리된 음원으로 나눕니다.
출력 데이터: Open-Unmix의 출력은 분리된 음원의 주파수-시간 스펙트로그램입니다. 이 스펙트로그램을 ISTFT(Inverse Short-Time Fourier Transform)을 사용하여 시간 도메인 신호로 변환할 수 있으며, 이로써 분리된 음원을 얻을 수 있습니다.
Open-Unmix는 다중 음원 분리 작업에서 뛰어난 성능을 보이는 모델 중 하나이며, 음악 분리, 음성 합성, 음성 변환 및 오디오 효과 처리와 같은 다양한 오디오 처리 작업에 활용됩니다. 모델의 성능 및 정확도는 데이터, 하이퍼파라미터 설정, 학습 데이터 및 모델 아키텍처에 따라 달라질 수 있습니다.
Spleeter VS Open-Unmix
두 모델 모두 주파수 도메인에서 오디오 신호를 분리하기 위한 모델입니다.
Spleeter는 주로 2차원 컨볼루션 신경망을 사용하여 오디오 신호를 분리합니다. 이러한 CNN 모델은 주파수 및 시간 차원에서 입력 신호를 분석하며, 주파수 분리 작업을 수행하기 위해 주파수 구성 요소를 추출합니다.
그러나 2차원 컨볼루션 네트워크는 커널 크기에 따라 특정 주파수 구성 요소에 대한 정보를 다루기 어려울 수 있습니다. 특히 작은 커널 크기를 사용하는 경우, 주파수의 낮은 또는 높은 부분에서 발생하는 고조파나 고주파수 성분의 정보를 충분히 포착하기 어렵습니다. 이로 인해 깨진 고조파 구조가 발생할 수 있습니다.
반면 Open-Unmix는 주파수 도메인 분리를 위해 주로 NMF(Non-Negative Matrix Factorization)를 사용합니다. NMF는 주파수 구성 요소를 양수로만 분해하여 분리 작업을 수행하며, 주파수 영역의 특성을 더 잘 보존할 수 있습니다. 따라서 NMF를 통해 더 나은 주파수 구성 요소 추출을 실현하며 보다 높은 품질의 출력을 얻을 수 있습니다.
NMF(Non-Negative Matrix Factorization)
NMF는 다양한 응용 분야에서 사용되는 선형 대수 기반의 행렬 분해 기술입니다. NMF는 양수만을 포함하는 두 개의 행렬로 주어진 입력 행렬을 근사화합니다. 이를 통해 원본 데이터의 특성을 추출하고 데이터를 더 해석 가능한 형태로 분해하는 데 사용됩니다.
- 행렬 분해: NMF는 하나의 입력 행렬을 두 개의 양수 행렬인 W(가중치 행렬)와 H(특성 행렬)으로 분해합니다. 즉, 주어진 입력 행렬 V를 다음과 같이 근사화합니다. V ~= WH
여기서 W와 H는 양수만을 가집니다.W(가중치 행렬): 입력 데이터를 어떤 특성으로 분해할지를 결정하는 요소입니다. 각 열은 데이터의 특성을 나타냅니다.
H(특성 행렬): 특성들을 조합하여 입력 데이터를 재구성하는데 사용됩니다.
비모수 제약: NMF는 양수만을 가지는 행렬을 사용하므로, 음수 값이 없고 특성 간의 선형 결합만으로 데이터를 근사화합니다. 이 비음수 제약은 데이터의 의미있는 특성을 추출하고 해석하기 쉽게 만듭니다.
- 목적 함수 최적화: NMF는 목적 함수(비용 함수)를 최적화하여 입력 데이터와 근사화된 데이터의 차이를 최소화합니다.
일반적으로 사용되는 목적 함수 $$ min | V - WH |, where V, W, H >= 0
Mask
“Mask”는 오디오 신호 처리에서 특정 주파수 영역 또는 시간 영역에서 어떤 부분을 제거하거나 강조하는데 사용되는 값입니다. 예를 들어, 음성 분리 작업에서 “마스크”는 주파수 도메인 또는 시간 도메인에서 원본 음원과 다른 부분을 나타내는데 사용됩니다. 일반적으로 마스크 값이 1에 가까울수록 해당 영역의 신호가 강조되고, 0에 가까울수록 해당 영역의 신호가 억제됩니다. 마스크는 원하는 특정 작업을 위해 신호를 조작하거나 추출하는 데 유용하게 사용됩니다.
충분히 높은 마스크 값을 가지는 주파수 성분은 원본과 유사한 형태로 출력되며, 다른 주파수 성분과 거의 상호 작용하지 않습니다. 따라서 간섭이 거의 없습니다. 낮은 마스크 값을 가지는 주파수 성분은 원본과 강력한 상호 작용하며, 다른 주파수 성분과 간섭이 높게 나타납니다. 이로 인해 간섭이 발생하며, 주파수 성분 간의 혼란이 발생할 수 있습니다.
Mask Warping
오디오 신호 처리나 음성 분리와 관련된 작업에서 사용되는 기술 중 하나입니다. 이것은 주파수 도메인에서 생성된 마스크를 조정하는 과정을 의미합니다.
주파수 도메인에서 생성된 마스크는 특정 주파수 영역에서 어떤 부분을 추출하거나 억제하는 데 사용됩니다. 그러나 때로는 원하는 결과를 얻기 위해서는 이 마스크를 조정해야 할 수 있습니다. 예를 들어, 원하는 음성을 분리하거나 노이즈를 줄이기 위해 마스크를 사용하는 경우, 마스크의 형태나 특성을 변경하여 더 나은 결과를 얻을 수 있습니다.
Mask Warping은 주로 비선형 함수를 사용하여 마스크를 변형하는 것을 의미합니다. 이것은 주파수 도메인에서 특정 주파수 성분을 더 강조하거나 더 억제하려는 경우에 사용됩니다. 이러한 왜핑은 원하는 결과를 얻기 위해 마스크를 조절하고 최적화하는 데 도움이 됩니다. 예를 들어, 주파수 영엿에서 생성된 마스크를 특정 주파수 대역을 더 강조하거나 부드럽게 만들기 위해 비선형 함수를 적용할 수 있습니다. 이로써 노이즈를 더 효과적으로 제거하거나 원하는 음성을 더 정확하게 추출할 수 있습니다.
Normalization gain
정규화 게인 또는 정규화 계수로, 입력 신호의 음량을 조정하는 데 사용되는 값입니다. 이 게인은 음량 조절에 필요한 계산을 수행하는 데 도움을 주는 요소입니다.
목표 음량(target loudness): 원하는 목표 음량 레벨을 나타냅니다. 일반적으로 음악이나 오디오 신호의 목표 음량을 설정하는 것이 필요할 때 사용됩니다. 목표 음량은 신호를 어떤 레벨로 조정하려는지를 나타냅니다.
통합 음량(integrated loudness): 오디오 신호의 전체적인 음량 수준을 나타내는 측정값입니다. 통합 음량은 일정 기간 동안의 오디오 신호의 평균 음량을 계산한 값으로, 신호의 전체적인 음량 특성을 표현합니다. 통합 음량은 오디오 신호의 음량을 정량화하거나 비교하는 데 사용됩니다.
정규화 게인은 주로 입력 신호의 통합 음량과 목표 음량 간의 차이를 계산하여 입력 신호를 목표 음량으로 조정하는 데 사용됩니다. 이것은 오디오 처리나 음향 엔지니어링에서 특정 음량 레벨을 유지하거나 조절할 때 유용한 도구 중 하나입니다.
먼저, 입력 신호의 통합 음량($L_I$)을 측정하거나 계산합니다. 이것은 입력 신호의 전체적인 음량 수준을나타냅니다.
다음으로, 원하는 목표 음량 레벨($L_T$)을 설정합니다. 이것은 입력 신호를 어떤 음량 레벨로 조정하려는지를 나타냅니다.
그런 다음 정규화 게인($g_{LN}$)은 다음과 같이 계산됩니다. $g_{LN} = 10^{(L_T - L_I) / 20}$
계산된 정규화 게인(g_{LN})은 입력 신호의 각 샘플 또는 프레임에 곱해집니다. 이렇게 하면 입력 신호의 음량이 목표 음량 레벨로 조정됩니다.