
이번에는 A Robust Vocal And Accompaniment Separation System Using Gated CBHG Module And Loudness Normalization 논문 리뷰를 진행해보겠습니다.
이 논문은 음원 분리 기술에 대한 내용을 다룹니다. 약간 생소할 수 있는 용어가 나오기 때문에 간단하게 도움이 될 만한 용어들을 POST에 정리해두었으니 참고하시면 좋을 것 같습니다.
Abstract
오디오 신호 처리 분야에서, source separation은 오랜 시간 진행되어왔던 연구 주제이며, 최근에 deep neural network를 도입하여 중요한 성능 개선을 보여주었습니다.
본 논문에서는 GSEP(Gaudio 소스 분리 시스템)을 소개하며, 이는 GatedCBHG 모듈, mask warping 및 loudness normalization(음량 정규화)를 사용한 견고한 음성 및 반주 분리 시스템으로서, 객관적 측정 및 주관적 평가 모두애서 최신 시스템을 능가한다는 것을 보여줍니다.
Introduction
본 논문은 음성 및 반주 분리 모델의 기준을 robustness(견고성), 품질 빛 비용 측면에서 정의하였습니다.
첫째, 이 모델은 다양한 종류의 오디오 신호에 대해 강한 내구성을 가져야 합니다. 음량 차이에 대해서도 모델은 안정적인 성능을 내야 합니다.
둘째, 이 모델은 최신 기술과 동등하거나 뛰어난 음질을 제공해야 합니다. 이를 평가하기 위해 SDR(Source to Distortion Ratio)와 SIR(Source to Interface Ratio)와 같은 객관적인 측정 지표를 사용합니다.
마지막으로, 이 모델은 UHDTV부터 스마트폰까지 다양한 전자 제품에 구현될 수 있을 만큼 계산 효율적이어야 합니다.
본 논문에서는 이 세 가지 기준을 기반으로 하는 세 가지 주요 최신 소스 분리 모델인 Open-Unmix, Demucs, Spleeter에 대해 설명되며, 새로운 모델을 제안합니다.
Observations and Design Principles
2.1 Robustness in Loudness
본 논문은 최신 분리 모델이 입력 프로그램의 음량 차이에 대해 견고한지 확인하기 위해, MUSDB18 데이터 셋을 각 모델에 대한 음성 SDR을 -15, -30 및 -45 [LUFS]의 목표 음량으로 정규화한 후 측정했습니다. 음량 정규화 과정에서 각 단편의 통합 음량은 ITU-R BS.1770-3을 따라 측정되었습니다.
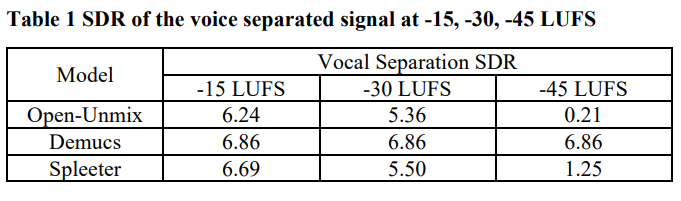
Open-Unmix 모델은 입력 음량에 상대적으로 민감하여 낮은 입력 음량에서는 성능이 감소할 수 있습니다. Demucs 모델은 전처리 및 후처리 로직에 의존하여 입력 신호의 크기나 음량에 상대적으로 덜 민감하게 동작합니다. 이러한 특성때문에 Demucs 모델은 다양한 입력 음악 크기에 대해 일관된 분리 성능을 제공할 수 있습니다.
2.2 Sound Quality Enhancement for Real Application
음원 분리에서 SDR과 SIR은 두 가지 인기 있는 측정 항목이며 더 높은 SDR과 SIR을 가지는 분리된 신호가 더 나은 음질을 제공할 수 있지만, 실제 음악 분리 시스템은 지각적인 음질을 평가하기 위해 청취자의 주관적인 평가 및 음성 처리 기술을 통합하여 고려해야 합니다.
2.2.1 Time domain model VS Frequency domain model
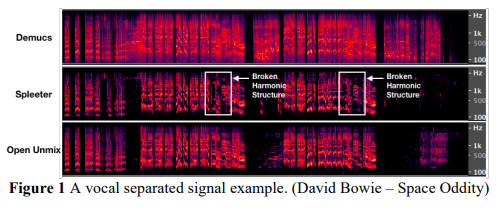
Demucs와 Wave-U-Net과 같은 시간 영역 모델은 그림에 나타난 것처럼 Open-Unmix나 Spleeter와 같은 주파수 영역 모델보다 더 와이드 밴드 노이즈를 생성합니다. 이러한 현상은 시간 영역 모델의 회귀 오차가 샘플 단위의 불연속성을 가져오는 반면 주파수 영역 모델의 경우 STFT 프레임 단위의 불연속성을 가져온다는 것으로 설명될 수 있습니다. 또 다른 가능한 설명은 시간 영역 모델이 주파수 모델에서의 시간에 따라 변하는 신호를 처리함으로 인한 급격한 불연속성을 부드럽게 보간하는 ‘overlap-and-add’ 방법을 갖고 있지 않을 수도 있습니다. Karaoke 시장에서는 노이즈 관점에서 주파수 영역 모델이 더 안정적임을 발견했습니다.
2.2.2 Kernel design
Open-Unmix와 Spleeter 두 개의 주파수 도메인 모델을 비교할 때, Spleeter의 출력 신호는 종종 그림에 나타난 것처럼 깨진 고조파 구조(broken harmonic structure)를 갖습니다. Spleeter에서 사용된 2차원 컨볼루션 네트워크가 커널 범위를 벗어나는 낮은 또는 높은 주파수 구성요소에서 유용한 정보를 놓치기 때문입니다. 커널 크기를 더 크게 사용하여 이 문제를 해결할 수 있지만, 이로 인해 모델 복잡성이 증가합니다. 출력 신호의 안정성을 위해 본 논문은 기준 시스템으로 1차원 모델인 Open-Unmix를 선택했습니다.
2.2.3 Interference
기준 시스템인 Open-Unmix는 Demucs와 Spleeter와 비교하여 더 낮은 SIR을 보였습니다. Open-Unmix의 신호 분석 블록은 skip connection이 있는 세 개의 LSTM으로 구성되어 있어 불필요한 신호의 간섭을 제거하는 데에는 충분하지 않을 수 있습니다. 더 나은 음성 활동 감지 및 특징 추출을 위해, 본 논문은 gated convolutions, highway networks, GRU(gated recurrent networks)와 같은 게이팅 구성 요소를 더 정교하게 조합하여 사용했습니다.
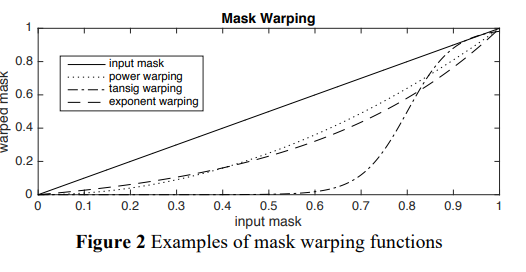
간섭을 줄이는 또 다른 방법으로 보수적인 방식으로 mask를 warping했습니다. Open-Unmix의 soft mask는 회귀로 훈련되므로 시간-주파수 영역에서 낮은 마스크 값을 가지는 입력 신호는 높은 간섭을 가질 가능성이 높습니다. 비선형 함수를 사용하여 마스크를 warping하면 간섭을 줄일 수 있습니다. 아래 그림은 비선형 mask warping 함수 예제를 보여줍니다.
2.3 Computational Efficiency
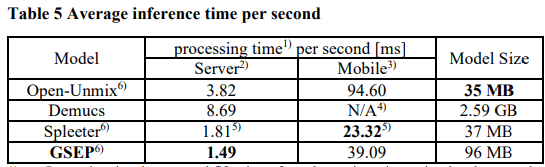
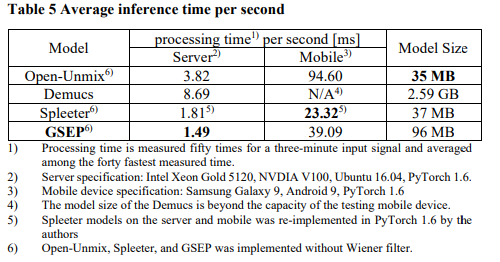
벤치마크 테스트로 Open-Unmix, Demucs 및 Spleeter가 GPU 서버 및 모바일 장치에서 실행될 때 입력당 평균 추론 시간을 측정했습니다. GPU 서버에서 측정할 때, 입력에 대해 1.8~8.7 [msec]의 처리 시간을 소비했습니다. 모바일 장치에서 구현할 때, Open-Unmix와 Spleeter는 각각 94.6 및 23.32 [msec]를 소비했습니다. Demucs는 모델 크기가 테스트한 모바일 장치의 용량을 초과하기 때문에 모바일 장치에 구현할 수 없었습니다.
3. Proposed Separation System
3.1 System Architecture
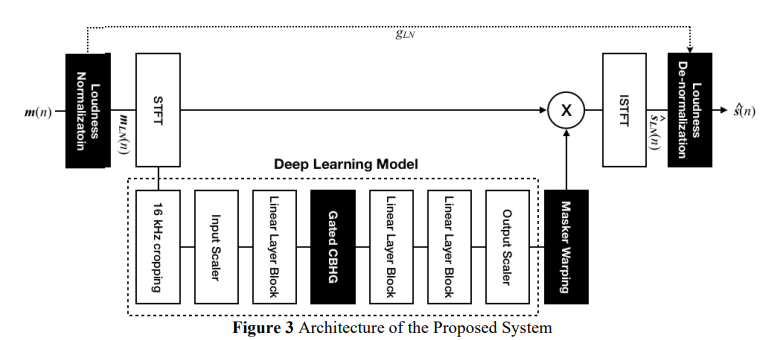
본 논문에서 제안된 분리 시스템의 아키텍처 구조입니다.
혼합물의 음량 차이에 대한 강건성을 위해 loudness normalization(음량 정규화) 및 denormalization(역정규화) 쌍이 사용되며, 더 나은 특징 분석과 발음/발음이 아닌 감지를 위해 Gated CBHG가 설계되었으며, 원치 않는 원본의 간섭을 줄이기 위해 mask warping이 추가되었습니다.
3.1.1 Loudness normalization and de-normalization pair
입력 혼합물 $ m(n) $은 목표 음량에 정규화되고 정규화된 음량 입력 신호 $ m_{LN} (n) $ 은 딥 러닝 모델의 입력으로 사용됩니다. 소스 분리 후 분리된 모델 출력 신호 $ \hat s_{LN} (n) $은 loudness normalization gain $ g_{LN} $을 사용하여 분리된 시스템 출력 신호 $ \hat s(n) $으로 다시 de-normalization됩니다. 여기서 normalization gain은 목표 음량 $ L_T $와 통합 음량 $ L_I $에 대한 $ g_{LN} = 10^{(L_T - L_I) / 20} $으로 정의됩니다.
3.1.2 Deep Learning Model with Gated CBHG
본 논문에서 제안된 딥 러닝 모델과 Open-Unmix의 차이점은 3-Layer LSTM 대신 CBHG(CNN-BiLSTM-Gated Linear Units) 모듈을 사용한다는 점입니다. CBHG 모듈은 문자 수준의 neural machine translation을 위해 처음 소개되었으며 또한, Tacotron과 같은 음성 합성 모델에서 텍스트 인코딩 및 멜 스펙트로그램에서 리니어 스펙트로그램으로 변환에 사용되었습니다. CBHG 모듈을 사용하여 주어진 혼합 스펙트로그램의 컨텍스트를 분석하고, CBHG의 컨볼루션 레이어에 Gated Linear Unit(GRU)을 추가하여 음성/음성이 아닌 신호 감지 능력을 향상시켰습니다.
CBHG 모듈의 입력과 출력 차원은 512입니다. 컨볼루션 블록은 8개의 컨볼루션 레이어로 구성되며, 각 커널의 폭은 1에서 8까지이며 채널 크기는 256입니다. max pooling은 시간 축을 따라 수행되며 풀링 크기는 2입니다. 1차원 projection 이후 residual connection을 위한 출력 차원은 512입니다. highway network 내부 레이어의 차원은 512입니다. 양방향 GRU에서 각 방향의 hidden size는 256이며 최종 출력 크기는 512입니다.
- Gated CBHG
음성 처리 및 텍스트 처리와 같은 다양한 응용 분야에서 사용되는 딥러닝 모델 중 하나로, 특히 음성 신호의 특성 추출 및 다양한 음성 처리 작업에 적합한 모듈
Convolutional Banks, Highway Networks, Gated Recurrent Units, Bidirectional GRU(Gated Recurrent Unit)의 약자.
- Convolutional Banks(CB)
- 입력 신호에서 다양한 크기의 커널을 사용하여 다양한 주파수 특성을 추출합니다.
- 각 커널은 입력 신호를 스캔하고 필터링하여 주파수 도메인에서 중요한 정보를 추출합니다.
- 여러 커널의 출력을 수집하여 주파수 정보를 종합합니다.
- Highway Networks
- Highway Networks는 CB의 출력을 처리하고 정보의 흐름을 제어하는 역할을 합니다.
- Highway Networks는 정보를 통과시키거나 거부하는 게이트 메커니즘을 사용하여 입력 데이터의 중요성을 조절합니다.
- 이렇게 하면 모델이 입력 데이터의 다양한 특성을 적절하게 활용할 수 있습니다.
- Gated Recurrent Units(GRU)
- GTU는 CBHG 모듈 내에서 시계열 데이터의 특성을 추출하는 데 사용됩니다.
- GRU는 순환 신경망(RNN)의 한 변형으로, 입력 데이터의 순서를 고려하면서 정보를 처리합니다.
- GRU는 hidden state를 업데이트하고 이전 타임 스텝의 정보를 현재 타임 스텝으로 전달합니다.
- Bidirectional GRU(Bi-GRU)
- Bi-GRU는 GRU의 양방향 버전으로, 입력 데이터를 순방향과 역방향으로 동시에 처리합니다.
- 이것은 모델이 입력 데이터의 양쪽에서 정보를 추출하여 더 풍부한 컨텍스트를 얻을 수 있게 해줍니다.
Gated CBHG 모듈은 입력 신호에서 다양한 주파수 특성과 시간적 특성을 추출하고 이러한 정보를 활용하여 음성 신호를 효과적으로 처리합니다. 음성 합성, 음성 인식, 음성 변환 및 음성 분석과 같은 다양한 음성 처리 작업에 사용됩니다. 이 모듈은 음성 처리 관련 딥러닝 모델에서 중요한 부분을 담당하며, 높은 성능과 효율성을 제공합니다.
3.1.3 Mask Warping
mask warping에 대해 간단한 거듭제곱 함수 $ f(x) = x^{\alpha} $를 선택했습니다. 여기서 알파($ \alpha $)는 warping 강도 비율을 나타냅니다.
3.2 Training Details
음성 추출을 위한 하나의 모델과 반주 추출을 위한 모델 두 개를 학습시켰습니다. 이 모델들은 MUSDB18 및 추가 데이터 셋(3000개의 개인 음악 및 공개 스피치 데이터 셋인 LibriSpeech와 KsponSpeech)으로 학습되었습니다.
각 학습용 오디오 세그먼트는 다음 단계를 따라 음량 정규화와 증강을 고려하여 생성되었습니다.
무작위로 음성 원본을 선택하고 음량을 0 LUFS로 조정합니다.
무작위로 음성이 아닌 세 개의 원본을 선택하고 음량을 -12 LUFS에서 12 LUFS 사이의 임의의 값으로 조정합니다.
조정된 음량을 가진 소스들을 섞습니다.
학습 시, batch 당 80개의 오디오 세그먼트가 사용되었으며 평균 제곱 오차(Mean Square Error)가 손실 함수로 사용되었습니다. 학습률은 1e-3이고 가중치 감소(Weight Decay)는 1e-5인 Adam 옵티마이저가 사용되었습니다. 학습률은 PyTorch 프레임워크의 ReduceLROnPlateu 스케줄러에 의해 조절되었으며, 감마(gamma)가 0.9, decay patience가 140, cooldown이 10으로 설정되었습니다. 학습 중에는 음량 정규화 쌍이 -13 LUFS의 목표 음량($ L_T $)을 가지도록 사용되었으며 마스크 왜핑 블록은 우회되었습니다.
3.3 Inference
모델은 -13 LUFS 프로그램을 최적화하기 위해 음량 정규화 쌍을 목표 음량 $ L_T $로 사용해야 하며, mask warping block을 사용합니다.
4. Experiment
제안된 시스템의 음질을 평가하기 위해, 10명의 청취자가 ITU-R BS.1534-3에 따른 두 가지 청취 테스트를 진행했습니다. 시스템의 입력 혼합 신호를 ‘믹스 참조’로 정의하고 청취자에게 각 테스트 신호가 믹스 참조에서 청취자가 상상하는 음성 또는 반주에 얼마나 가까운 지를 평가하도록 했습니다.
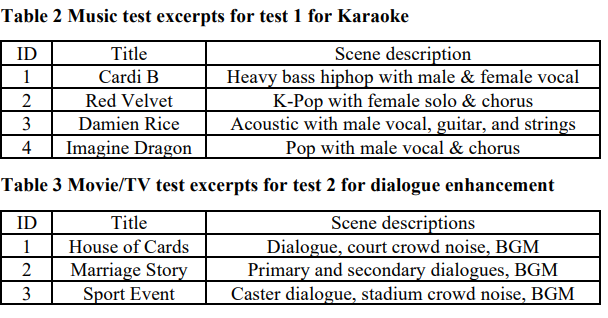
테스트 세트는 (1) 노래의 반주를 위한 노래방 용 반주 분리 및 (2) 대화 향상을 위한 영화/TV에서의 음성 분리로 구성되어 있습니다. 테스트 단편은 MUSDB18이 아닌 현실 세계의 음악과 프로그램에서 선택되었습니다.
테스트로서 네 가지 조건을 비교했습니다.(GSEP, Demucs, Wiener 필터가 있는 Open-Unmix 및 Wiener 필터가 있는 Spleeter)
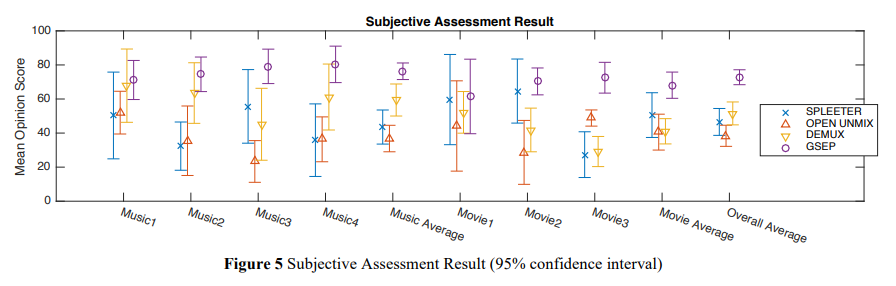
주관적 평가 결과는 아래 그림에 나타나며, GSEP가 모든 7개의 단편에 대해 가장 높은 MOS(Mean Opinion Score) 값을 보여 더 나은 음질을 제공한다는 것이 확인되었습니다. 특히 영화 단편 2와 3의 경우, GSEP가 크게 더 나은 품질을 보이는데, GSEP가 영화 3의 관객 소음을 제거하고 영화 2의 경우 주요 대화보다 음량이 상대적으로 낮은 보조 대화를 유지했기 때문입니다. 다른 모델은 이를 수행하지 않았습니다.
4.2 Objective Evaluation
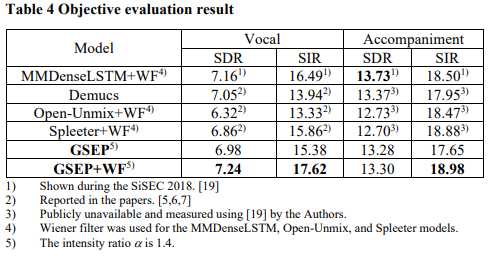
분리 성능에 대한 객관적 평가를 위해 GSEP의 SDR 및 SIR을 다른 모델들과 비교했습니다. 아래 표에서 GSEP 및 GSEP+WF는 Wiener 필터없이 제안된 모델, Wiener 필터가 있는 모델을 나타냅니다. 표에서 볼 수 있듯이, 제안된 시스템이 객관적인 측정에서 동등하거나 더 높은 분리 품질을 만족시키는 것이 확인되었으며, GSEP는 Wiener 필터 없이도 경쟁력 있는 SDR 및 SIR을 갖고 있습니다. GSEP+WF는 가장 높은 음성 SDR, 음성 SIR 및 반주 SIR을 갖고 있으며, 반주 SDR에서는 세 번째로 높습니다.
아래 표에서 나타난 것처럼 계산 효율성 측면에서 제안된 시스템이 GPU 서버에서 가장 낮은 처리 시간을 기록했으며, 모바일 기기에서는 두 번째로 낮은 처리 시간을 기록했습니다.
5. Conclusion and Future Works
GSEP는 노래방 및 대화 향상 시스템을 위한 강건성, 음질 및 비용 측면에서의 원칙으로 설계되었습니다.
음량 차이에 대한 강건성
동등하거나 더 나은 음질
다양한 시장 요구를 지원하기 위한 낮은 계산 복잡성
이러한 원칙에 따라 GSEP 시스템은 loudness normalization, gated CBHG, mask warping을 구현했습니다. 객관적 및 주관적 평가를 통해 이러한 원칙이 모두 만족되었음을 확인했습니다.
마치며
새로운 분야에 대한 논문이라 기본 배경지식에 대해 더 많이 공부해야 했습니다.
모델 구조를 수정하여 기존 모델보다 좋은 성능을 낸 기술 논문인 것으로 생각합니다.