
이번에는 AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문 리뷰를 시작해보겠습니다.
Abstract
Transformer 아키텍처는 자연어 처리 작업에서 표준적인 방법이 되었지만, 컴퓨터 비전 분야에서는 컨볼루션 아키텍처가 여전히 주류로 사용되고 있습니다.
비전 분야에서는 어텐션(attention)이 컨볼루션 네트워크와 함께 적용되거나, 컨볼루션 네트워크의 일부 구성 요소를 대체하기 위해 사용됩니다.
본 논문은 이미지 패치(sequence of image patches)에 직접 적용된 순수 Transformer가 CNN에 의존하지 않고도, 이미지 분류 작업에서 매우 훌륭한 성능을 발휘할 수 있음을 보여줍니다.
Transformer는 CNN에 내재된 일부의 귀납 편향(inductive biases)인 변환 등위성(translation equivariance)과 국소성(locality)과 같은 특성을 갖지 않기 때문에 데이터가 부족하게 훈련된 경우 일반화(generalization)가 제대로 이루어지지 않을 수 있습니다.
✏️ Inductive Bias
머신러닝 모델이 학습할 때 특정 가정이나 선입견을 가지고 학습하는 것
이는 모델이 데이터로부터 일반화를 추론하는 데 도움을 주는 미리 정의된 가정이나 제한 사항
즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정!CNN의 inductive bias
Spatial Hierarchy: CNN은 입력 데이터를 계층적 구조로 처리합니다. 하위 레이어에서는 작은 지역적 패턴을 감지하고, 상위 레이어로 갈수록 더 큰 공간적 패턴 및 추상적인 특징을 학습합니다. 이러한 계층 구조는 이미지의 공간적 특성을 효과적으로 인식하고 시각적 정보를 추출하는 데 도움을 줍니다.
Weight Sharing: CNN은 합성곱 연산을 통해 입력 데이터에 대한 가중치(필터)를 공유하여 특징 추출을 수행합니다. 이는 입력 이미지의 다양한 위치에서 동일한 패턴을 인식할 수 있도록 도와주며, 가중치 공유는 네트워크의 파라미터 수를 줄여 효율성을 높입니다.
Pooling: CNN에는 풀링 계층이 포함되어 있어 공간적 차원을 축소하고 위치 불변성을 제공합니다. Max Pooling 및 Average Pooling과 같은 풀링 연산은 주변 영역의 정보를 요약하여 노이즈를 줄이고 중요한 특징을 강조합니다.
Local Receptive Fields: 각 뉴런은 입력 이미지의 receptive field 영역에만 반응합니다. 뉴런이 특정한 지역 패턴을 인식하고 다른 지역에 대한 정보를 무시하는 것을 의미합니다.
Translation Invariance: CNN은 합성곱 및 풀링 연산을 통해 입력 데이터의 이동에 대한 불변성을 제공합니다. 객체나 패턴의 위치가 변경되더라도 모델이 동일하게 인식할 수 있도록 돕습니다.
Translation Equivariance: 입력 데이터가 이동하면 모델의 출력도 해당 이동만큼 변화합니다. 입력 이미지의 위치에 따하 feature map이 이동한 위치에 대응하여 패턴을 인식합니다.
Hierarchical Feature Learning: CNN은 다양한 레이어에서 다양한 수준의 특성을 추출하므로 이미지의 다양한 추상적 표현을 학습할 수 있습니다. 이러한 계층적 특성 학습은 객체 인식 및 이미지 분류와 같은 작업에 유용합니다.
Vision Transformer는 이미지를 패치로 분할하고 패치간의 관계를 학습하는 self-attention 기반 Transformer 아키텍처를 사용합니다.
ViT는 이미지를 픽셀 레벨이 아니라 패치 레벨에서 처리하기 때문에 CNN의 공간적인 구조에 대한 inductive bias를 직접적으로 갖지 않습니다.
대신, ViT는 self-attention을 통해 입력 패치간의 관계를 학습하여 이미지에서 패턴 추출합니다.
대규모 데이터로 pre-trained된 후 downstream task로 transfer되는 경우, ViT는 inductive bias를 능가하여 우수한 결과를 달성합니다.
대규모 데이터로 학습할 경우, inductive bias가 부족한 문제를 조금은 완화할 수 있습니다.
충분한 크기의 데이터 셋에서 pre-training한 후, 적은 데이터 셋을 가진 task에 fine-tuning을 시킬 경우에 좋은 성능이 나타나게 됩니다.
✏️ 일반적으로 많은 데이터를 사용하면 모델이 더 많은 패턴과 구조를 학습할 수 있으므로 일반화 능력이 향상될 수 있습니다.
일부 CNN 아키텍처는 작은 데이터 셋에서는 효과적으로 작동하지만 대규모 데이터 셋에서는 복잡한 패턴을 잡아내지 못할 수 있습니다.(CNN의 공간적인 구조나 지역성에 의존하는 특성 때문)
대규모 데이터 셋에서 훈련되는 모델(ViT)은 데이터의 다양한 샘플을 포착하고 다양한 상황에서 일반화할 수 있는 능력을 갖게 됩니다.
이를 통해 inductive bias 부족 문제를 완화합니다.
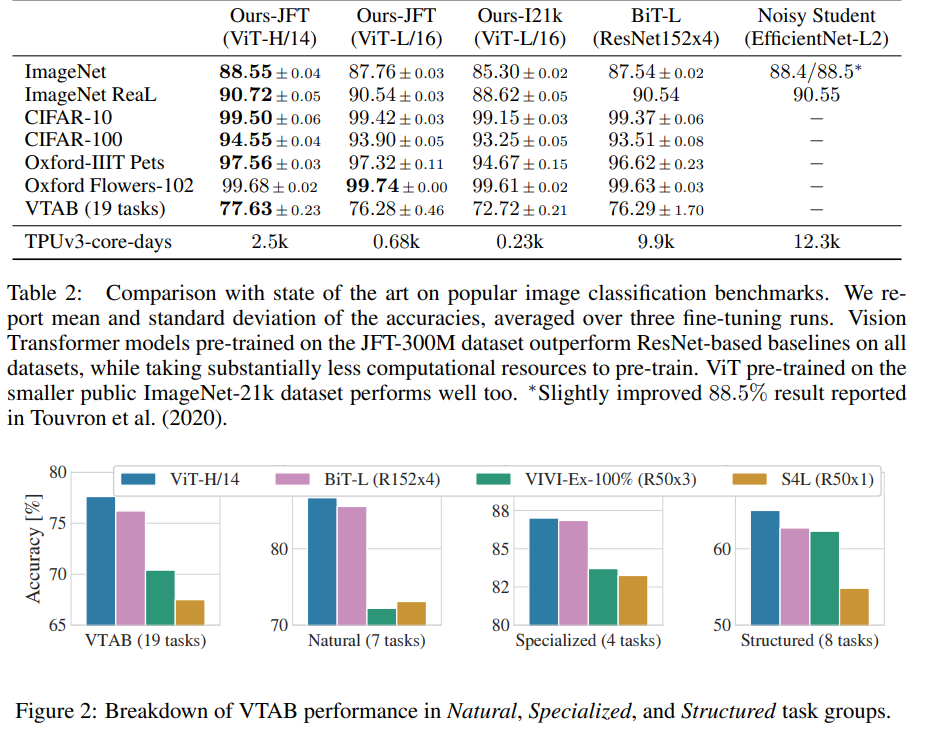
특히, 최고의 모델은 ImageNet에서 88.55%의 정확도, ImageNet-ReaL에서 90.72%의 정확도, CIFAR-100에서 94.55%의 정확도, 그리고 VTAB 스위트의 19개 작업에서 77.63%의 정확도를 달성했습니다.
Model Architecture
본 논문은 원래의 Transformer 구조를 최대한 따르도록 합니다.
ViT는 Transformer의 Encoder만 사용한 구조입니다.
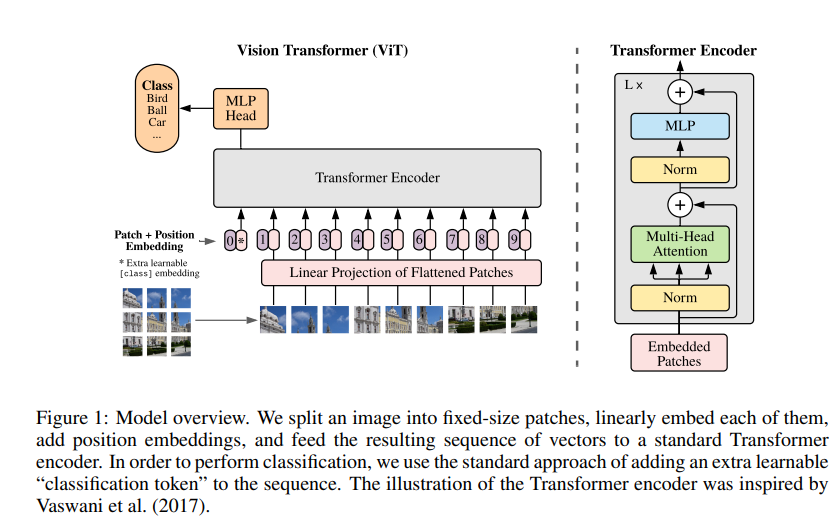
Patch Embedding
(H, W, C) 차원의 이미지를 (P, P) 크기인 패치 N개로 나눈 후 (P x P x C) 차원으로 flatten합니다. $ (H, W, C) \rightarrow (N, (P^2 \times C)) $
(H, W)는 원본 이미지의 해상도, C는 채널 수를 의미합니다.
(P, P)는 각 이미지 패치의 해상도를 나타냅니다.
$ N = HW / P^2 $ 으로 입력 시퀀스 길이를 의미합니다.
Linear projection을 통해 일정한 사이즈 D차원 벡터로 매핑합니다. $ (N, (P^2 \times C)) \rightarrow (N, D) $
✏️ D는 ViT 모델의 하이퍼파라미터입니다.
일반적으로 D가 크면 모델은 더 많은 특성을 표현할 수 있지만, 모델의 크기와 계산 비용이 증가합니다.
D가 작으면 모델의 표현력이 제한될 수 있지만, 모델의 크기와 계산 비용을 줄일 수 있습니다.따라서 적절한 균형을 찾는 것이 중요합니다.
일반적으로 대규모 데이터 셋과 복잡한 작업에서는 큰 D를 사용하는 것이 유리합니다.
[class] Token
BERT의 [class] 토큰과 유사하게, 이미지의 class를 구분하기 위해 학습 가능한 Embedding patch $ (Z_0^0 = x_{class}) $를 추가해줍니다. $ (N, D) \rightarrow (N+1, D) $
- $ z_L^0 $: 최종 L번째 layer의 0번째 Token
Pre-training 및 Fine-tuning 모두 classification head가 $ z^0_L $ 에 연결됩니다. Pre-training 과정에서는 classification head가 하나의 은닉층을 가지는 MLP로 구성됩니다. 즉, 분류 작업을 위한 복잡한 네트워크로 구성됩니다. Fine-tuning 과정에서는 classification head가 단일 선형 layer로 단순한 형태로 변경됩니다.
이것은 Fine-tuning 시에 더 간단한 classification head를 사용하여 모델을 목표 작업에 더 잘 맞출 수 있도록 하는 전략입니다.
Position Embedding
Patch Embedding에 Position Embedding을 추가하여 위치 정보를 유지합니다.
2D position embedding을 사용해도 상당한 성능 향상을 관찰하지 못했기 때문에 학습 가능한 1D position embedding을 사용합니다.
✏️ 1D position embedding
- 이미지를 패치로 나누어 각 패치에 대한 위치 정보를 인코딩할 때 사용합니다.
- 패치의 순서 또는 위치에 따라 각각의 패치에 고유한 위치 임베딩 벡터를 할당하여 표현하는 방식입니다.
2D position embedding
- 이미지를 행과 열의 좌표로 구성된 그리드로 변환할 때 사용합니다.
- 각 좌표 위치에 대해 행과 열의 임베딩 벡터를 결합하여 해당 위치를 표현하는 방식입니다.
이렇게 얻은 임베딩 벡터 시퀀스를 인코더의 입력으로 사용합니다.
Encoder
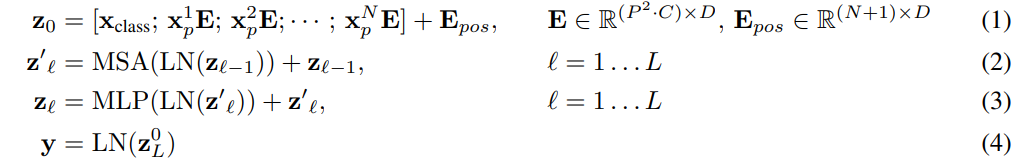
Transformer 인코더는 Multi-Head Self-Attention(MSA)과 MLP 블록 (2, 3)이 번갈아가며 구성됩니다.
각 블록 이전에 Layer Normalization이 적용되고, 각 블록 이후에 잔차 연결(residual connection)이 이루어집니다.
MLP는 비선형 활성화함수 GELU를 가진 두 개의 layer로 구성됩니다.
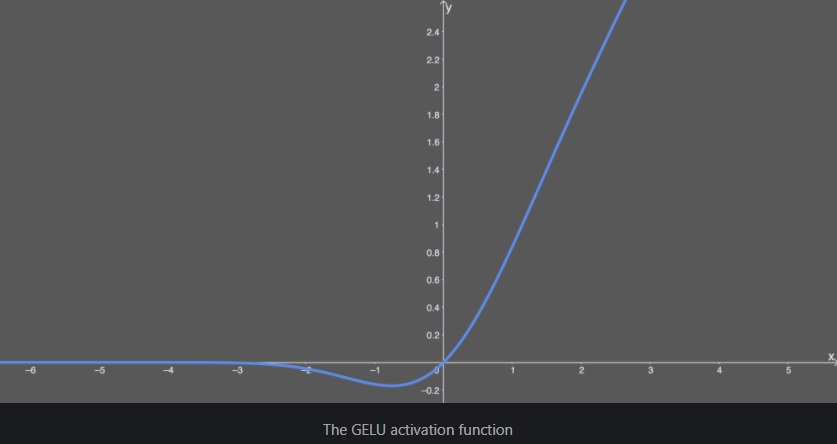
✏️ GELU(Gaussian Error Linear Unit)
- 비선형 활성화 함수
GELU 함수는 dropout, zoneout, ReLU 함수의 특성을 조합하여 유도되었습니다. GELU는 NLP 분야에서의 BERT, ALBERT 등 최신 딥러닝 모델에서 굉장히 많이 사용되고 있고, 본 논문인 ViT에서도 사용하고 있습니다.
먼저 ReLU 함수는 입력 x의 부호에 따라 1이나 0을 deterministic하게 곱하고 dropout은 1이나 0을 stochastic하게 곱합니다.
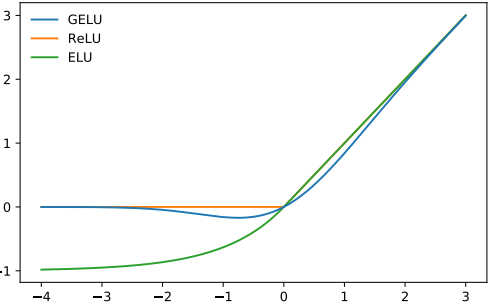
GELU에서는 이 두 개념을 합쳐 x에 0 또는 1로 이루어진 마스크를 stochastic하게 곱하면서도 stochasticity를 x의 부호가 아닌 값에 의해서 정하게 됩니다.![fig9]()
GELU가 RELU, ELU 등의 다른 활성화 함수들보다 빠르게 수렴하며, 낮은 오차를 보여줍니다.
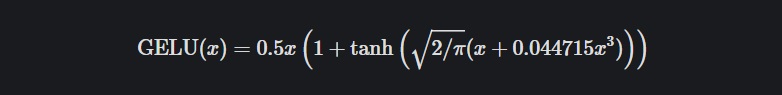
Inductive bias
Vision Transformer는 CNN에 비해 이미지에 특화된 inductive bias가 훨씬 적습니다.
CNN에서는 앞서 설명한 것 처럼 각 레이어에 locality, two-dimensional neighborhood equivariance, 그리고 translation equivariance의 inductive bias가 전체 모델에 걸쳐 각 레이어에 고정되어 있습니다.
반면에 ViT는 MLP 레이어만이 locality와 translation equivariance를 가지며, self-attention 레이어는 global합니다.
two-dimensional neighborhood 구조는 매우 제한적으로 사용됩니다. 모델의 시작 부분에서 이미지를 패치로 자르기 위해 사용되며, fine-tuning을 위해 다른 해상도의 이미지에 대한 위치 임베딩을 조정하는 데 사용됩니다.
Position Embedding 초기화 시 패치의 위치에 대한 정보를 전달하지 않으며, 패치간의 모든 공간적 관계는 처음부터 학습되어야 합니다.Hybrid Architecture
Image Patch 대신 CNN의 feature map에서 입력 시퀀스를 사용할 수 있습니다.
이 모델에서는 패치 임베딩 프로젝션이 CNN feature map에서 추출된 패치에 적용됩니다.
특수한 경우로, 패치는 Spatial Size가 1X1일 수 있는데, 이는 input sequence가 feature map의 spatial dimension을 단순히 flatten하고, Transformer 차원으로 투영시킴으로써 얻어지는 것을 의미합니다.
FINE-TUNING AND HIGHER RESOLUTION
일반적으로, 대규모 데이터 셋에서 ViT를 Pre-training하고, (더 작은) 하위 작업에 대해 Fine-tuning합니다.
이를 위해 사전 학습된 prediction head를 제거하고, 제로로 초기화된 D x K feed-forward layer를 추가합니다.
여기서 K는 downstream의 클래스 수를 나타냅니다.
보통 pre-training보다 높은 해상도에서 fine-tuning을 수행하는 것이 효과적입니다.
높은 해상도의 이미지를 사용하여 Fine-tuning을 수행하게 되면 더 많은 공간적인 세부 정보를 활용하여 더욱 정확한 패턴 및 특징을 학습할 수 있습니다. 또한 객체의 위치와 크기에 대한 정보를 더욱 정확하게 전달할 수 있으며, 데이터의 다양성이 높아지므로 모델이 더 견고하게 작동하고 일반화할 수 있게 도와줍니다.
Vision Transformer는 임의의 시퀀스 길이를 처리할 수 있지만, 사전 학습된 position embedding은 더 이상 의미가 없게 됩니다. fine-tuning 단계에서 새로운 작업과 데이터에 맞추기 위해 position embedding을 조정해야 합니다.
따라서 원래 이미지에서의 위치 정보를 활용하여 사전 학습된 position embedding의 2D interpolation을 수행합니다. 기존 position embedding의 위치 정보를 유지한 채로 새로운 이미지의 위치에 대한 position embedding을 생성합니다.
이를 통해 ViT는 새로운 이미지에 대해 고정된 position embedding이 아닌 유동적인 위치 정보를 가지는 position embedding을 제공함으로써 fine-tuning 단계에서 다양한 해상도의 이미지에 적용할 수 있습니다.
이 해상도 조정과 패치 추출은 이미지의 2D 구조에 대한 inductive bias를 Vision Transformer에 수동으로 주입하는 유일한 지점입니다.
이렇게 함으로써 ViT는 inductive bias를 수동으로 주입하고, 모델이 이미지의 공간적인 정보를 활용할 수 있도록 합니다.
Experiment
Datasets
- Pre-Training
1,000 개의 클래스와 130만 개의 이미지로 구성된 ImageNet
21,000 개의 클래스와 1400만 개의 이미지로 구성된 ImageNet-21k
18,000 개의 클래스와 3억3천만 개의 고해상도 이미지로 구성된 JFT
- Transfer Learning
ImageNet, CIFAR 10/100, Oxford-IIIT Pets
Model Variants
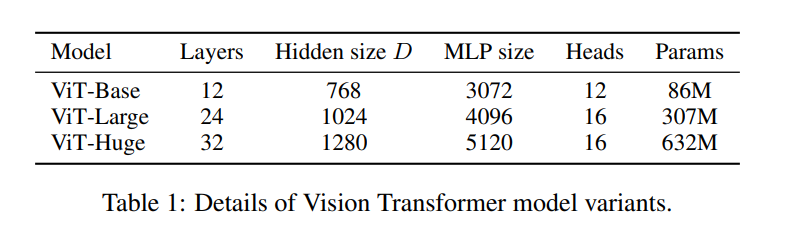
BERT에서 가져온 “Base” 및 “Large” 모델 외의 “Huge” 모델을 추가했습니다.
COMPARISON
PRE-TRAINING DATA REQUIREMENTS
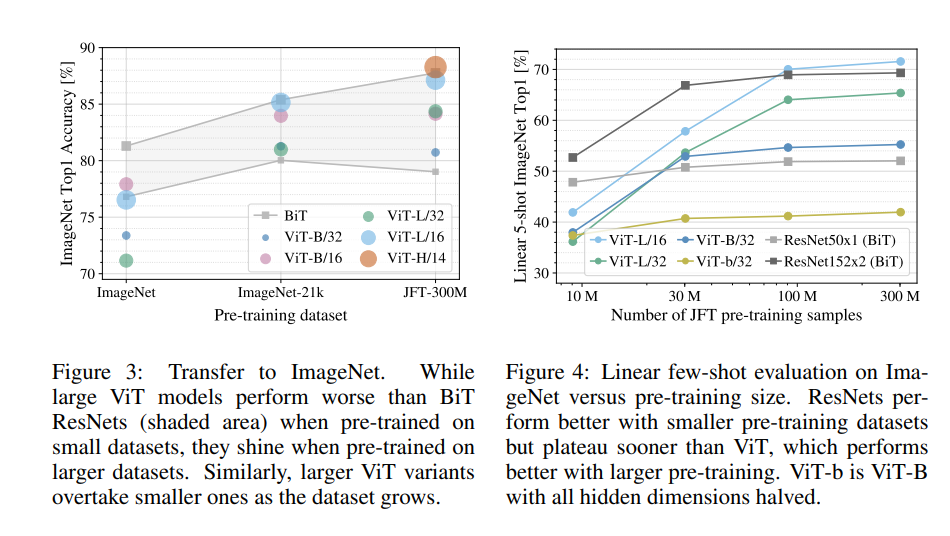
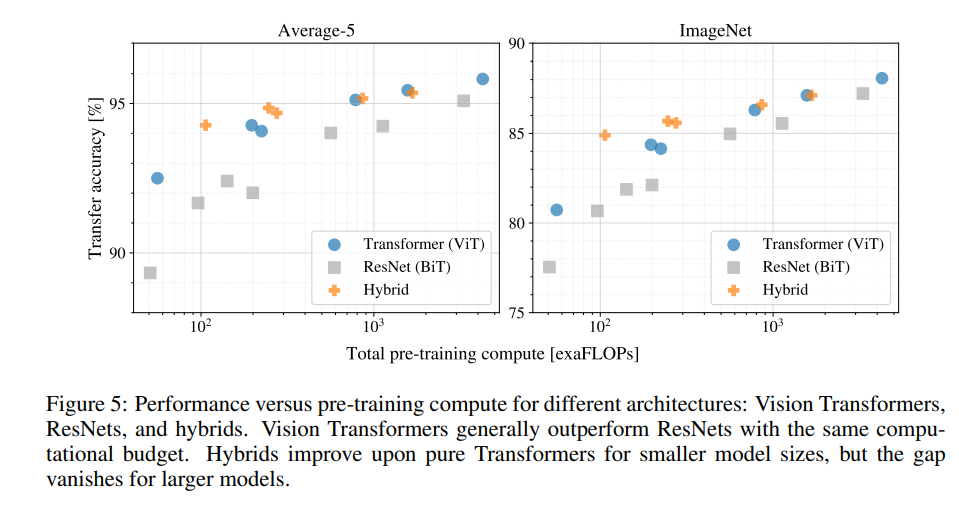
Pre-training data set의 크기가 커질수록 ViT의 성능이 더 좋아집니다. 가장 큰 데이터 셋인 JFT-300M에서 ViT가 BiT CNN을 능가합니다.
ViT는 작은 데이터 셋에서 비슷한 계산 비용을 가진 ResNet에 비해 과적합이 많이 발생합니다.
합성곱의 inductive bias이 작은 데이터 셋에 유용하지만, 큰 데이터 셋에서는 데이터로부터 직접 관련 패턴을 학습하는 것만으로 유익하다는 결과를 보여줍니다.
INSPECTING VISION TRANSFORMER

Vision Transformer의 첫 번째 레이어는 flatten된 패치들을 낮은 차원 공간으로 선형 투영합니다.
왼쪽 그림은 학습된 임베딩 필터의 상위 주성분들을 보여줍니다.
잘 학습된 CNN의 앞쪽 레이어를 시각화했을 때와 유사한 결과가 나타납니다.
잘 학습된 CNN과 같이 이미지에 필요한 edge, color 등의 low-level 특징들을 잘 포착하고 있음을 파악할 수 있습니다.
투영 이후에는 학습된 위치 임베딩이 패치 표현에 추가됩니다.
가운데 그림은 i번째 패치 행, j번째 패치 열에 대한 코사인 유사도 값의 히트맵으로 구성되어 있습니다.
위치 임베딩의 i번째 열, j번째 행 값이 이웃한 열, 행의 임베딩 값과 높은 유사도를 보임을 알 수 있습니다.
즉, 가까운 패치일수록 높은 유사도를 보여줍니다.
Self-Attention은 네트워크가 가장 최하위 레이어에서도 이미지의 전체적인(global) 특성을 파악할 수 있도록 합니다.
지역적 특성 또한 잘 잡아내며, layer가 깊어질수록 ViT 내부의 모든 헤드에서 대부분 전역적 특성을 잘 잡아냄을 알 수 있습니다.

CONCLUSION
ViT는 이전의 컴퓨터 비전에서 self-attention을 사용한 작업과 달리, 초기 패치 추출 단계를 제외하고는 이미지에 특화된 inductive bias를 아키텍처에 도입하지 않았습니다.
대신, 이미지를 패치의 시퀀스로 해석하고 NLP에서 사용하는 표준 Transformer 인코더로 처리합니다.
이 전략은 대규모 데이터 셋에 대한 사전 학습과 결합할 때 매우 잘 작동합니다.
따라서 Vision Transformer는 많은 이미지 분류 데이터 셋에서 SOTA 기술을 능가하는 성과를 보이며, 비교적 저렴한 사전 훈련 비용을 가집니다.
Image Recognition 분야에 Transformer를 직접적으로 적용한 첫 사례입니다.